More on verifying backlink cloaks
The nature of cloaked backlinks is to hide the offending content (links) from human visitors to the page and only deface the page when it is visited by a known web crawler (e.g. Google, Bing, Yahoo, etc).
If you suspect that your site has cloaked backlinks, there are a few techniques you can use to try and verify the existence of the cloaking code.
Crawling the Filesystem
If you have access to the filesystem of the website, you can scan the files of the site for offending keywords. For example, for most Unix servers, if your site was installed in /var/www/vhosts/ :
egrep -ir 'viagra|cialis|lavitra' /var/www/vhosts/
would do a recursive, case-insensitive scan of your website, looking for files containing any of the words "viagra", "cialis", or "lavitra" (all of which are common in cloaked ads).
More complicated cloak code, particularly cloaks written in php, try to obfuscate their source code, and more than likely will use base64 encoding to hide their code from simple searches (as above). Given the rarity of base64 encoding in everyday programming, you may find it useful to scan for the use of the php functions used to decode base64 content and then execute the resulting code. For example, scanning for base64_decode function calls :
grep -r 'base64_decode' /var/www/vhosts/
and then looking in any resulting files for base64_decode calls inside of an eval function, e.g. :
eval(base64_decode('woerij234sdoijoiw...
If you find some base64 encoded content in a file on your server, you can do manual decoding of the base64-encoded payload via various web-based base64 decoders, such as this one at Opinionated Geeks.com.
A more general recommended practice is to develop a set of suspicious terms and code fragments (such as base64_decode) and periodically (via cron) scan your website's files, sending notification of any positive results.
User agent impersonation
Simple cloaks reveal their payload only to known web crawlers as identified by the HTTP User Agent of the request. It is possible for you to impersonate the User Agent of popular web crawlers to see what a given request returns. For example, when crawled by Google, your site sees requests from the User Agent :
Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
You can impersonate this with a command-line tool like, such as curl...
curl -A 'Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)'
http://some.url.edu/
...or via browser add-ons or features. For Firefox, one that seems to work well is User Agent Switcher. This will allow you to change Firefox's User Agent request header to that of Google's crawler. After installing the add-on, configure it as below :
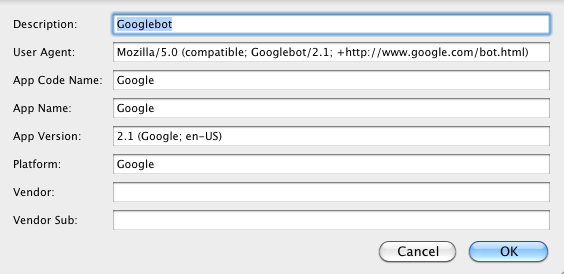
User Agent impersonation can be done with Safari without additional plugins, via its built-in Developer Tools. First, enable them in the Safari preferences/Advanced tab :
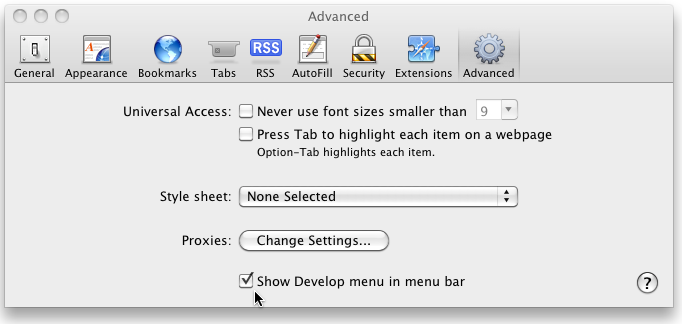
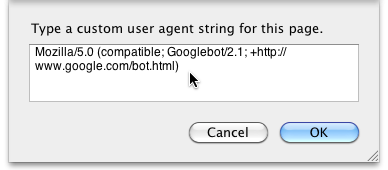
Next, select from the Developer menu, "User Agent/Other.." and enter the Googlebot User Agent :
Using the Google Webmaster Tools
More complicated cloaks rely upon checking the IP and/or hostname of the web client and matching it against a list of known IP prefixes or domain names. Only for those clients matching the filter are the cloaked contents displayed. For example, a cloak may contain a large array of valid IP prefixes and check the client against it :
$bot_list = array("8.6.48","62.172.199","62.27.59","63.163.102", ... );
$ip = preg_replace("/\.(\d+)$/", '', $_SERVER["REMOTE_ADDR"]);
if (in_array($ip, $bot_list)) {
// display payload
}
Without jumping through great technical hoops, the only way to trigger such a cloak would be to crawl the page from one of Google's IP addresses and search the output. Fortunately, Google allows this as part of their Google Webmaster Tools.
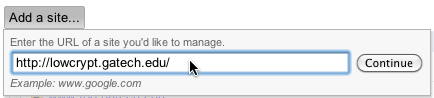
Before you are allowed to crawl your site as Google, you must verify to Google that you own the site. First log into the Webmaster Tools with a Google account and add a new host :
Next, choose one of several methods to "prove" to Google that you own the site :
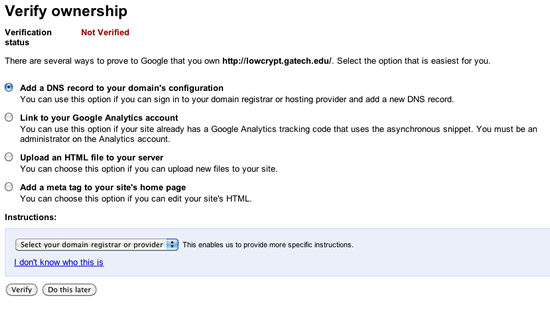
Once verification is complete, from the site's Dashboard, you can choose the site, click on "Diagnostics/Fetch as Googlebot" ...
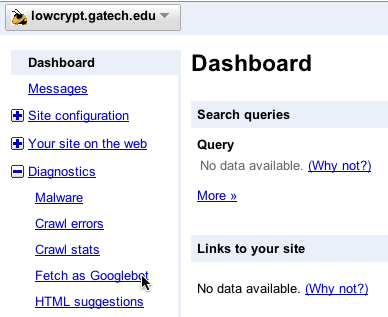
...choose a url to crawl, and Google will queue the request. Once the page has been actually crawled by Google, you see a "Success" link...

...that when clicked, gives you back the response headers and content returned by the request :
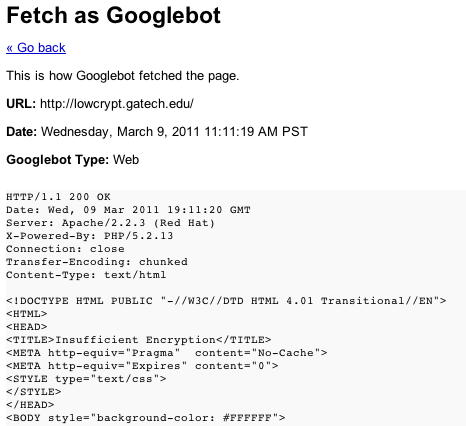
You would then want to scan the output Google returns for suspect keywords.
Does the crawl actually come from a real Googlebot? Looking at lowcrypt.gatech.edu's access log for the request above, we do indeed find :
66.249.71.237 - - [09/Mar/2011:14:11:20 -0500] "GET /robots.txt HTTP/1.1" 404 473
"-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
66.249.71.237 - - [09/Mar/2011:14:11:20 -0500] "GET / HTTP/1.1" 200 3876
"-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"
(Note: 66.249.71.237 is crawl-66-249-71-237.googlebot.com)
If lowcrypt's index page had an IP or domain-based cloak, this crawl from Google should trigger it (of course, there is always the risk that the list of IP prefixes included in a cloak are out of date with what Google is actually using to crawl; int hat case you would get a false negative when searching for a cloak. If you are worried about that, then do several such actual Google crawls, in hopes of getting a Googlebot IP that is in the cloak).